Research
Dr. Buehrer's research interests span a broad range of wireless communications and sensing problems including:
- Cognitive Radio
- Position Location
- Interference Cancellation
- Dynamic Spectrum Access
- Cognitive Radar
- Machine Learning Applied to Communications, Radar & Localization
- Next G Cellular/Communication Systems
Dr. Buehrer's research has been sponsored by the following companies and agencies:
- National Science Foundation
- Army Research Office
- NIST
- DARPA
- Office of Naval Research
Position-location has historically been a desired feature in many commercial and military applications. Navigation was the primary use of position information with man-made systems being used as early as the 1950’s (e.g., Loran-C Navigation system) and exploding with the advent of the Global Positioning System (GPS). More recently, position location has been an active area of research in many areas including cellular E-911, sensor networks, ad hoc networks, robotics, and ubiquitous computing. Current applications of PoLoNets include inventory control, home automation, safety networks, tracking personal items, personnel monitoring, command and control in emergency situations, the guidance of robots in remote locations, and many others. In fact, the IEEE 802.15.4a standard, a standard for low power, low-data rate wireless is primarily focused on position location applications.
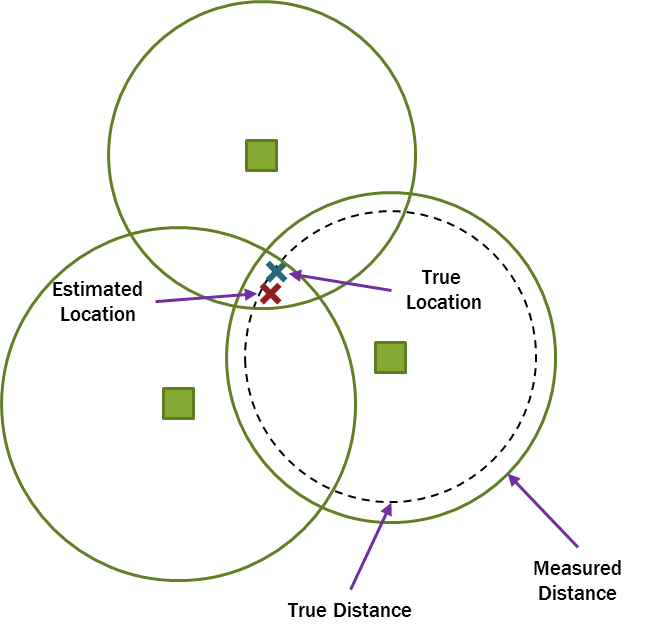
In outdoor environments, accurate position information can be obtained via GPS. However, there are many situations where GPS is either unreliable (e.g., indoor scenarios), or impractical (e.g., where GPS receivers are too bulky or expensive), requiring the development of other solutions. As one example, consider the command and control of a firefighter operation where multiple personnel are deployed into a building. For safety and efficiency purposes, it would be extremely helpful for a command center outside the building to be established for not only communication but also position tracking as shown in the Figure below. In such a case, we require an ad hoc position location and communication network that is independent of GPS and is not reliant on pre-existing infrastructure.
Recently, wireless sensor networks (WSN) have been the subject of great interest in many studies because of their wide applications in control, tracking, and monitoring. Location information is a vital aspect of many WSNs. Indeed, the location of each sensor is often required to make the collected information useful. Generally, in a WSN, the positions of a number of sensors are known (anchor nodes), while there are some sensors (source nodes) whose positions are unknown and thus must be estimated using sensor localization. The main purpose of sensor localization is to determine the location of sensors in a WSN via noisy measurements. These measurements may include received signal strength (RSS), time-of-arrival, time-difference-of-arrival , and angle-of-arrival. Among the different types of measurements, RSS is a popular method mainly because of its low complexity and cost in software and hardware implementations.
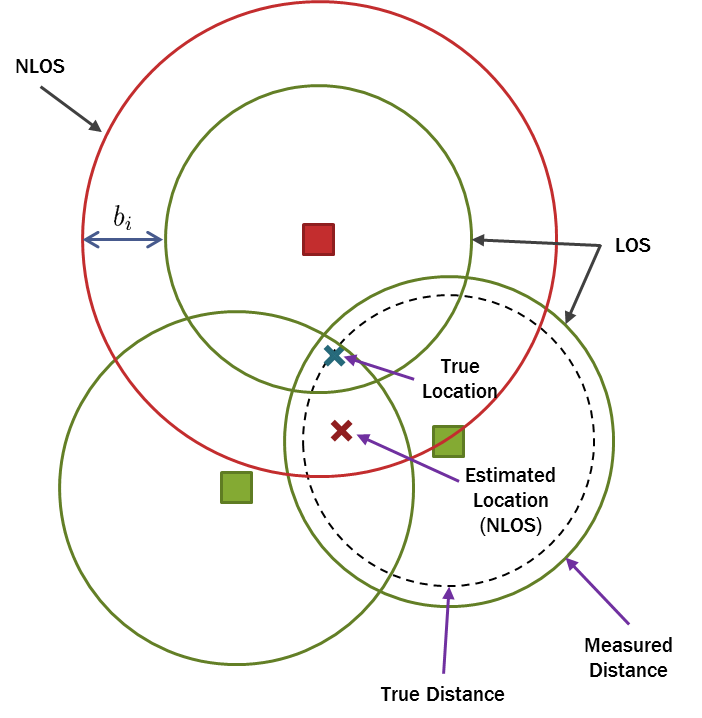
Sensor localization is more beneficial in indoor environments where using the Global Positioning System (GPS) is impractical. However, in such environments, most connections among sensors are non-line-of-sight (NLOS). When the line-of-sight (LOS) path among sensor nodes is blocked, NLOS propagation occurs. Localization accuracy is severely diminished from NLOS connections, since they have large bias errors which make the measured pair-wise distances much larger than their true values. NLOS problem can be divided into the three main scenarios. First, the estimator knows which connections are NLOS and also their distribution. In this scenario, the optimal performance is obtained if the exact distribution of NLOS is determined and considered in the estimator. Second, the estimator knows which connection are NLOS but their distribution is not known. It can be shown that the optimal performance in this scenario is obtained by the ML estimator neglecting NLOS connections and use only LOS connections. However, when sub-optimal estimators are used, using NLOS connections along with LOS ones can improve the performance. Moreover, the probability of incorrect identification is always non-negligible in this scenario. It is possible that a LOS connection is misidentified as a NLOS connection (false alarm) or vice versa (missed detection) which might significantly decrease estimation accuracy. Third, the estimator knows neither which connections are NLOS nor their distribution. The optimal accuracy is hard to define in this scenario, since it is difficult to distinguish NLOS connections. Robust estimators are such as the M-estimator and least median of squares (LMS) algorithm.
Sensor localization can be divided into two general cases: non-cooperative and cooperative. Source nodes are only connected to anchor nodes in the non-cooperative case. Moreover, the position of each source node is estimated independently. In this case, each source node has to be connected to at least three anchor nodes in order to be localized without any ambiguity. However, this requirement does not meet in most networks. Therefore, the lack of accessible anchor nodes and also limited connectivity among anchor nodes and source nodes lead to the emergence of cooperative localization. In this case, source nodes are able not only to communicate with anchor nodes but also to other source nodes. As a result, two sets of measurements are available to the estimator; measurements between source nodes and anchor nodes (source-anchor measurements) and also measurements among source nodes themselves (source-source measurements). Furthermore, the algorithms proposed for cooperative localization are either centralized or distributed. In centralized cooperative algorithms, the measurements are sent to a central processor and the location of all source nodes are estimated simultaneously. Whereas in distributed algorithms, each source node is localized independently and estimated data are passed through the neighboring sensors. The distributed algorithms can also be implemented in a central processor, however, the location of source nodes are estimated one at a time and updated iteratively. Based on the CRLB and simulation results, it can be shown that both estimation performance and robustness are improved by employing cooperative localization.
We are currently working on the following topics
- Cooperative and noncooperative localization in non-line-of-sight environments
- Cooperative and noncooperative tracking in non-line-of-sight environments
- RSS-based localization in correlated shadowing
- Asynchronous TOA-based localization
The concept of a Cognitive Radio (CR) was originated by Joe Mitola who defines a CR as “a radio that is aware of its surroundings and adapts intelligently”. Mitola’s definition spans from identifying the radio operator's needs to using the best radio interface settings. A major portion of the work done in the field of CR pertains to the latter half of the above definition of CR, specifically concerning spectrum sensing, modulation classification, cognitive networks etc. where the main application is to make efficient use of the available spectrum. Another definition of CR from Tom Rondeau is “to build a flexible, reconfigurable radio that is guided by intelligent processing to sense its surroundings, learn from experience and knowledge, and adapt the communication system to improve the use of radio resources and provide desired quality of service.” Our research in this field is more related to the definition from Rondeau wherein we proposed a cognitive engine for link adaptation, that uses reinforcement learning techniques to adapt to the surrounding environment and learn from its experience.
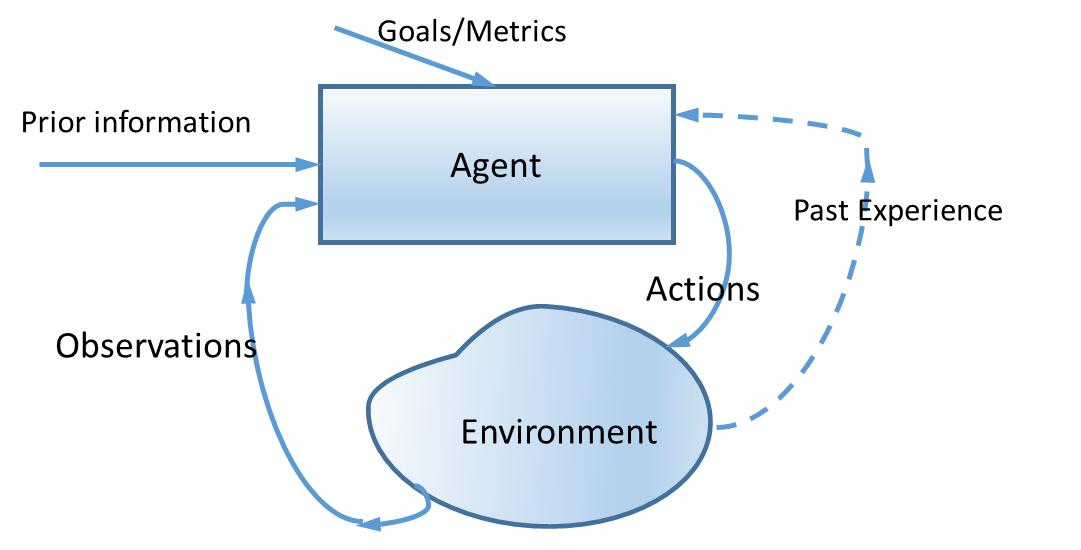
Cognitive Engine (CE)
A CE is an artificial agent that senses the environment and adapts its strategy. Much more than an adaptive system, a CE is capable of learning and adapting from past experiences. Learning is the process of estimating the mapping between input values to output values.
CE Design: A predict-then-adapt approach potentially fails in rapidly changing wireless environments. A CE senses the environment, uses an approach it learned in the past, and then re-learns from its new experience by (a) using experience-based reasoning or (b) going through cycles of exploration (search for new approaches) and exploitation (use the best approach previously learned).
CE Training: Training guides a CE through the process of learning a system’s behaviour in response to specific environment conditions. This can be achieved by (a) Supervised Learning where learning is based on known action-outcome mappings or (b) Reinforcement Learning where learning is based on previous experiences. The complexity of the training process increases with the number of possible approaches.
Main Tasks of a CE
A primary function of the CE is to learn the capabilities of the radio. This is generally done by trial and error. When the radio performs this function it is said to be exploring. On the other hand, when the radio is choosing methods with the best known performance it is said to be exploiting. However, the radio might not have the latter option if it does not know any satisfactory methods (i.e., it has not learned its performance for the situation that it is currently facing) and will have no choice but to explore. This operation consumes valuable resources such as time and energy and might significantly impact the link performance (i.e., dropped packets). One option to avoid these negative effects during the radio’s operation is to put the CE through prolonged training sessions covering most expected operating conditions. However, even if the CE is assumed to go through prolonged learning (exploration) sessions, it is practically impossible to expose it to all possible channel conditions a priori. Consequently, it is reasonable to expect that the CE sooner or later will face unknown conditions. In such a case, if the radio is operating in a critical mission it may not have the luxury of time to learn what is best before operating; it has to establish a connection and learn at the same time. Optimally balancing exploration vs. exploitation ensures that the negative effects of learning will be kept to a minimum. Therefore, we need to evaluate the performance of the radio controlled by the CE during learning.
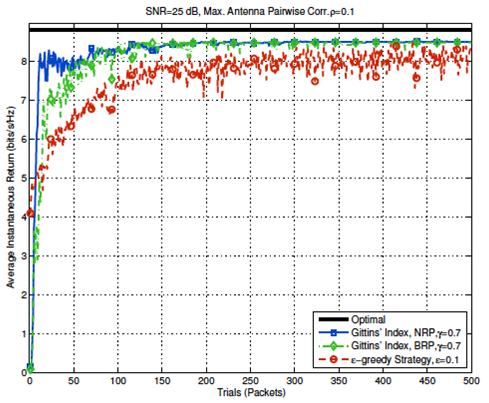
We propose a Gittin’s index-based strategy selection for MIMO Link adaption. The strategy with the best index is chosen at a given time in a particular state.
Current Research
CE-based Jamming/Anti-Jamming
- Devise an intelligent jammer (anti-jammer) that adapts its jamming strategy to disrupt potential jammers in the environment.
- For example, based on a metric such as BER/PER (PSR) /Capacity, choose jamming techniques such as pulse jamming/ tone jamming/ wideband jamming.
- For example, a Decision tree-based algorithm can be developed to learn the environment and optimize the jammers’ decision.
CE-based Localization
- Un-supervised clustering-based algorithms for localization, for example sensor node localization.
- Model-based multiple object tracking algorithms that learns by training or experience.
- Fingerprinting (for example RFID) based target identification and localization.
Traditionally, receivers have been designed to complete tasks such as synchronization, channel estimation, demodulation, and decoding in a sequential fashion. Optimal maximum a posteriori (MAP) or maximum likelihood (ML) detection of the information bits requires that these tasks be completed jointly which is prohibitively complex. The term iterative receiver refers to a communication receiver in which the MAP or ML estimate of the information bits is approximated using an iterative algorithm (i.e., using the turbo principle).
Next generation wireless communication systems are pushing the limits of both energy efficiency and spectral efficiency. Energy efficiency is aided by advanced error correction codes while spectral efficiency is aided by both higher order modulations, MIMO transmission, and the reduction of training overhead. These trends will challenge the radio receiver in functions such as frame synchronization, symbol and carrier recovery, equalization, and interference mitigation. Iterative receivers and, more generally, probabilistic processing show much promise for being able to harness the strength of the error correction code and approach MAP or ML performance in completing these tasks and recovering the transmitted information.
Our group’s research includes the following areas:
- Frame, symbol, and carrier synchronization
- Multi-user detection
- Equalization of MIMO transmissions
- Channel code construction for iterative processing
- Application of probabilistic graphical models including factor graphs and Bayesian networks
Distributed radar networks provide great benefits over single-node radars. The figure below demonstrates the improvement in tracking performance for network sizes of two, three, and four radars. The improvement from three to four radars is not as pronounced as from two to three, since the observation quality of the fourth radar is less than the others due to the environment configuration.
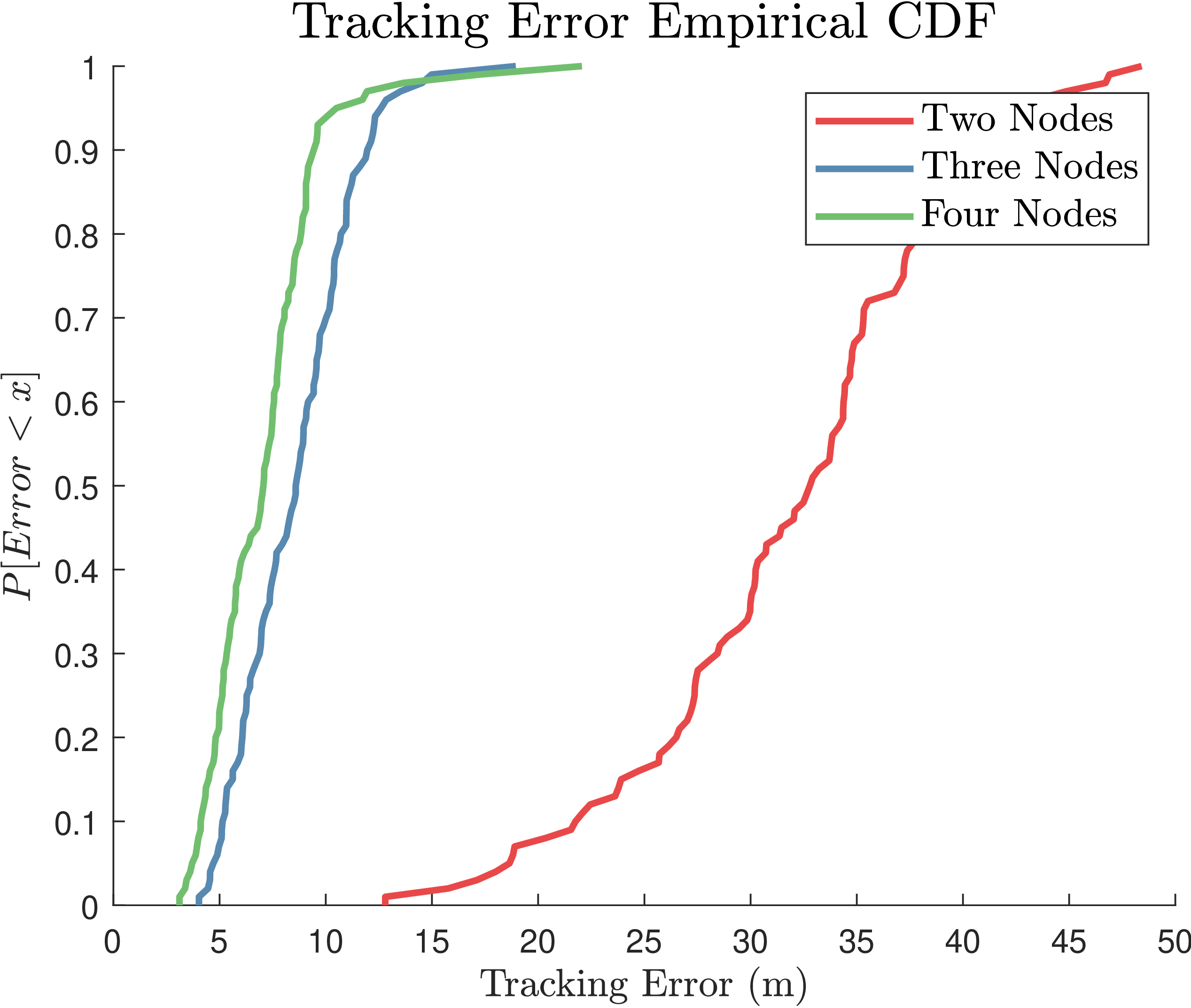
These improvements come at the cost of complexity: the network must account for coordination between radar nodes to avoid interference. In this thrust we develop cognitive techniques to solve coordination issues and improve performance using observations from the environment. The video below depicts the learning process of a radar network when an interferer enters the scene.

Radar Network Coexistence
The scenario begins with the radars operating in separate frequency bands. Then, a WiFi system enters the scene, causing interference to one of the radar nodes. This triggers the radar, and subsequently the entire radar network, to learn to avoid interference with the other radars and the WiFi system. The learning process is conducted in a distributed fashion, meaning radar nodes do not communicate with one another and there is no central coordinator. Instead, the radar nodes implicitly communicate with one another through collisions (interference events) to converge to the optimal channel selection.
The massive growth of communication systems, such as 5G, leads to more congested spectrum. Legacy systems are unable to adapt to congested spectrum, and their performance can severely degrade as a result. In this thrust, we investigate the benefit of cognitive radar compared to legacy radar systems. We address the following research problems using reinforcement learning:
- Can a radar's waveform control (e.g., interference avoidance) be enhanced through learning?
- How effectively can a radar learn to avoid dynamic (perhaps intentional) interference?
- How often should a radar avoid dynamic interference?
- How can future radar systems improve situational awareness?
Cognitive Radar for Interference Avoidance
The scenario below compares the performance of multiple cognitive radar techniques for dynamic interference avoidance:
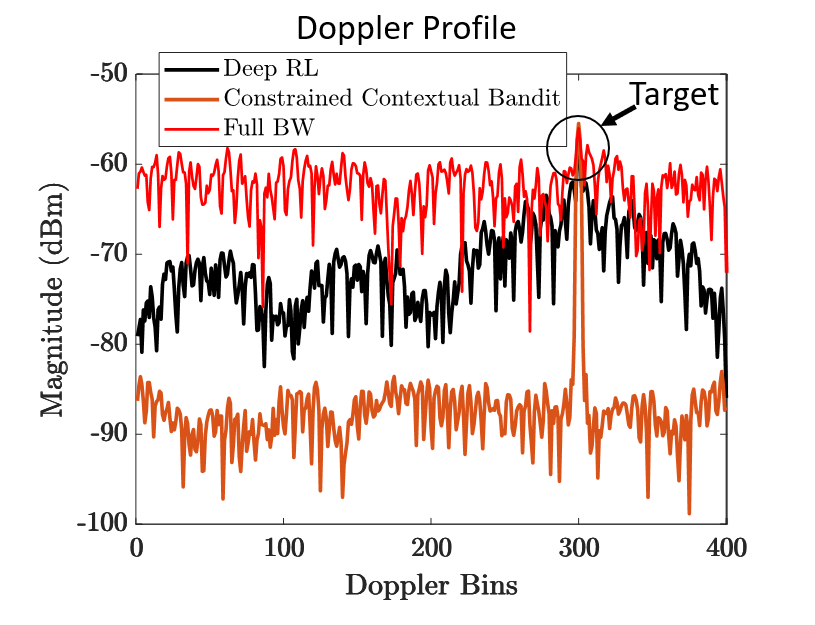
The "Full BW" strategy represents the approach used by legacy radar systems; the radar does not avoid interference and transmits using the full bandwidth available. The interference significantly degrades the radar return, causing the target to be lost in the high side-lobes.
The "Deep RL" (Deep-Q reinforcement learning) and "Constrained Contextual Bandit" perform better by dynamically avoiding interference. However, the bandit approach clearly performs best due to the low side-lobes and high target peak.
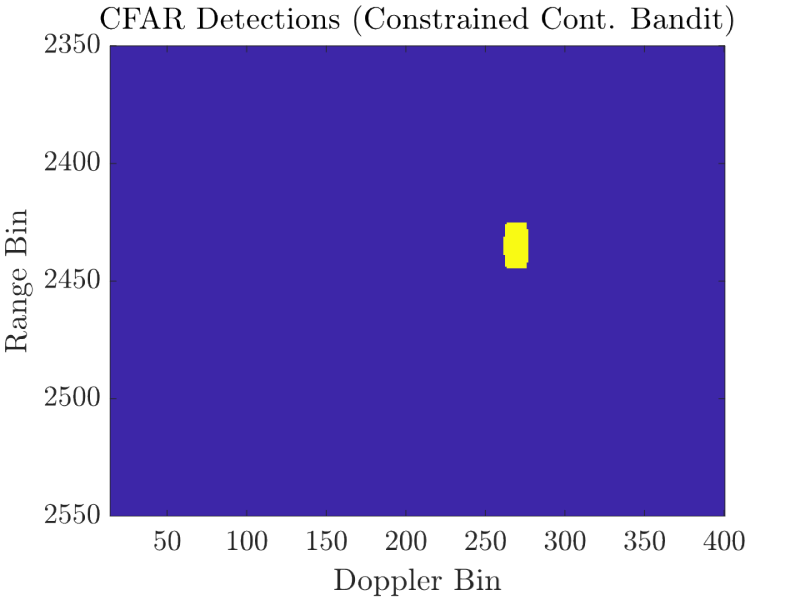
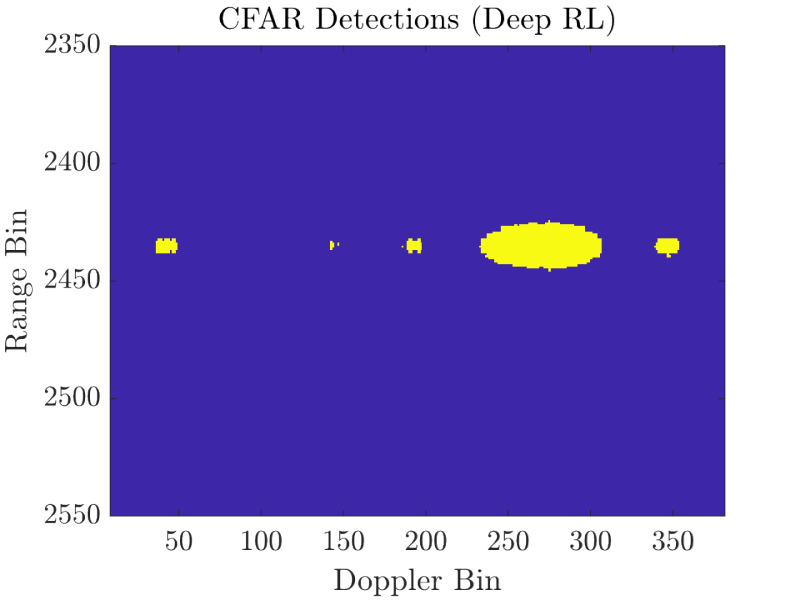
The two range doppler profiles above show the superiority of the constrained contextual bandit approach to cognitive radar. The low side-lobes and high peak result in a clear detection. Conversely, the high side-lobes of the deep learning approach lead to a wide target detection and multiple false alarms across the Doppler bins.
Improvements from cognitive radar translate to better target tracking. Cognitive radars are able to achieve lower tracking error by avoiding interference compared to a legacy (full band) radars, shown by the following video.
Cognitive Radar Tracking
Cognitive Radar for Clutter Mitigation
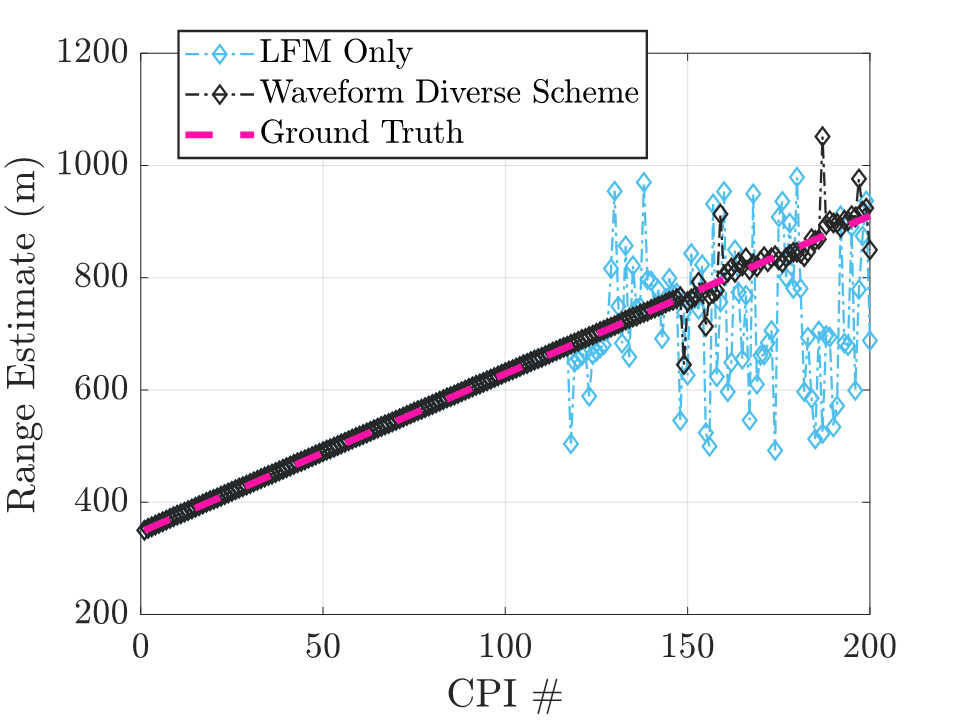
Another application of cognitive radar is optimal waveform selection in the presence of clutter (undesirable radar returns due to reflections from objects in the environment, i.e. buildings, landscape, weather, etc.) The figure below shows that a cognitive radar ("Waveform Diverse Scheme") has improved target tracking compared to a legacy radar ("LFM Only"), especially in the latter half of the track, when the channel quality begins to degrade: